
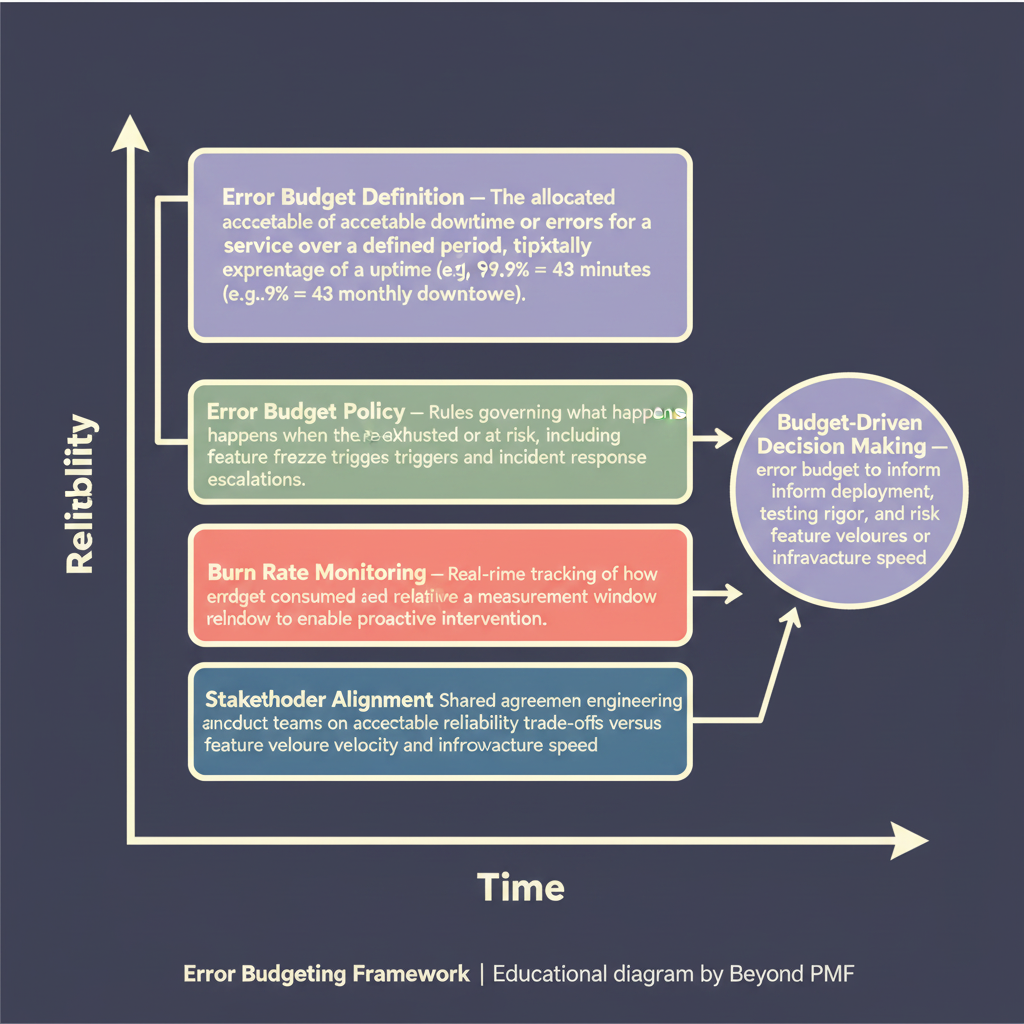
The Error Budgeting Framework is a strategic approach used primarily in site reliability engineering (SRE) to quantify the allowable amount of service downtime or errors in a given period. By setting a numerical limit on errors, teams can make informed decisions about the risks they can afford while pushing new features. This framework helps maintain a balance between reliability and the rapid deployment of new functionalities, ensuring customer satisfaction and system stability.
Define service level objectives (SLOs) that align with business goals. | Calculate the error budget based on these SLOs. | Monitor system performance and track errors against the error budget. | Implement policies for what happens if the error budget is exhausted. | Adjust development pace or reliability measures based on error budget consumption.
Regularly review and adjust SLOs to reflect actual user expectations | Integrate error budget metrics into daily operations | Foster a culture of accountability and transparency around reliability
Promotes a balance between innovation and reliability | Provides a quantitative measure to guide decision-making | Helps prioritize engineering efforts on reliability when necessary
Requires accurate setting and understanding of SLOs | Can be challenging to implement without mature monitoring tools | May lead to reduced innovation speed if not managed properly
In environments where reliability is critical to business operations | When introducing new features or services at a rapid pace
In early-stage development where rapid iteration is more valuable than stability | When the service impact of downtime is minimal or negligible